このエントリの目的は、SOA Suite11gのファイルアダプタおよびフォーマットビルダを使って、それぞれの注文を処理することです。以下のサンプルデータを使います。
001Square Widget 0245.98
102Triagular Widget 1120.00
403Circular Widget 0099.45
ORD8898302/01/2011
301Hexagon Widget 1150.98
ORD6735502/01/2011
このサンプルは、複数の明細データを持つ固定長データです。各注文データは3桁の数値で始まる品目データが1個以上含まれていて、その後に定数ORDで始まる1件のサマリーデータが続きます。
このファイルを処理して、最初のポーリングで1件目の注文データを取得するにはどうすればいいでしょうか。
001Square Widget 0245.98
102Triagular Widget 1120.00
403Circular Widget 0099.45
ORD8898302/01/2011
2件目の注文は?
301Hexagon Widget 1150.98
ORD6735502/01/2011
[メモ]1回のポーリングで1件以上のレコードを取得することもできます。この場合は、ファイルアダプタのStep 6/9のスナップショットにある「複数メッセージ」フィールドを確認してください。
この例で必要なもの
SOA Extension for JDeveloper 11.1.1.4.0をインストール済みのJDeveloper Studio Edition (11.1.1.4.0)
いずれもOTNからダウンロードできます。
なお、この手順を完成させたり、フォーマットビルダのテストを実施する上で、WebLogic Serverを起動する必要はありません。
ファイルアダプタを含むSOAコンポジットを作成する
フォーマットビルダはファイルアダプタの一部なので、新しいSOAプロジェクトとSOAコンポジットを作成するところからスタートです。
ここに簡単な手順をまとめました。
- JDeveloperを起動
- メインメニュー>ファイル>新規
- 新規ギャラリで[一般]カテゴリを開き、アプリケーションを選択し、右側のペインでSOAアプリケーションを選択し、[OK]を押す
- SOAアプリケーション作成ウィザードのStep1で、アプリケーション名とディレクトリを指定し、[次へ]を押す
- SOAアプリケーション作成ウィザードのStep2は、デフォルトのまま[次へ]を押す
- SOAアプリケーション作成ウィザードのStep3で、コンポジットの名前を指定して[終了]を押す
これらの手順を終了すると、新しいアプリケーションとSOAプロジェクトができあがります。このSOAプロジェクトにはcomposite.xmlファイルが含まれています。今回の例では手順を短くするため、MediatorやBPELプロセスを定義していませんが、今から作ろうとしているファイルアダプタを使うためには、MediatorやBPELプロセスが最終的には必要になります。
コンポーネントパレットからファイルアダプタのアイコンを、中央のペインの左側「公開されたサービス」もしくは右側「外部参照」のエリアにドラッグアンドドロップします(スナップショット中の緑の丸囲みを参照、この場合は「公開されたサービス」に配置)。左側にアダプタを配置すると、ファイルを処理してコンポジットに取り込みます。右側の場合はデータをファイルに出力します。
このときに、入出力とも同じフォーマットビルダの定義を利用することができます。 例えばコンポジットの左側でファイルアダプタとフォーマットを使って固定長データをXMLに処理し、コンポジットやBPELプロセス内でデータを変更して、コンポジットの右側でファイルアダプタと同じフォーマットを使い、同じ固定長データフォーマットにデータを書き出すこともできます。
ファイルアダプタをコンポジットに配置したら、ファイルアダプタ構成ウィザードが始まります。ようこそページは飛ばして、Step2でサービス名を指定し、[次へ]を押します。
Step3はデフォルトのまま[次へ]を押し、Step4では"Read File"を指定し、[次へ]を押します。
Step5では入力データが含まれているファイルの場所を指定し、[次へ]を押します。
Step6では、Step5で指定したディレクトリ中のどのファイルを入力ファイルとするかを指定します。今回は*.txtを指定しています。また、「ファイルが複数のメッセージを含む」フィールドのチェックがあり、[バッチでメッセージをパブリッシュする数]値に1が含まれていることを確認してください。この値を大きくすると、ファイルアダプタ1回のポーリングで取得できる論理注文グループデータを増やすことができます。つまり、ファイルアダプタを使って処理するMediatorやBPELプロセスの各インスタンスに流れる注文の個数を決定する値なのです。
Step7はデフォルトのまま[次へ]を押します。
Step8では、画面右側の歯車アイコンを押して、ネイティブフォーマットビルダを起動します。
ネイティブフォーマットビルダでの作業
フォーマット作成に入る前に、手順をまとめておきます。
方法(ボトムアップ)
注文データは品目データとサマリーデータで構成されているという前提で…
- 品目データ、サマリーデータと別々の複合タイプ(itemRecord、summaryRecord)をつくる
- 上で定義した複合タイプを束ねるグループのデータタイプ(LogicalOrderRecord)を作る。
- ルート要素(order)を定義する。このorderのデータ型はLogicalOrderRecord。
フォーマット定義
Step1では、[新規作成]、[複合タイプ]を指定し、[次へ]を押します。
Step2ではこのエントリのはじめに見せたテストデータを含むファイル(サンプルデータはこのエントリの最後にダウンロードできるようにしてあります)を選択、確認して、[次へ]を押します。
Step3では入力データ各々の複合タイプを定義する必要があります。ルート要素を選択して、複合タイプを追加するアイコン

をクリックします。
アイコンをクリックすると、新しい空の複合タイプの定義が作成されます。一番簡単に定義を作成する方法は、サンプルデータの1行目を選択してドラッグし、<new_complex_type>にドロップすることです。
フォーマットビルダはデータを検知して、フィールドを特定するグリッドが現れます。ここで[複合タイプ名]を”itemRecord”に変更します。
その後、ルーラーをクリックして固定列の位置を指定します。必要であれば、赤の三角形アイコンをいじって正しい位置に設定します。既存の赤の三角形をダブルクリックすると、不要なエントリを削除することもできます。下の例の場合、0桁から3桁、4桁から28桁、29桁から行の最後までの3個のフィールドを定義しています。
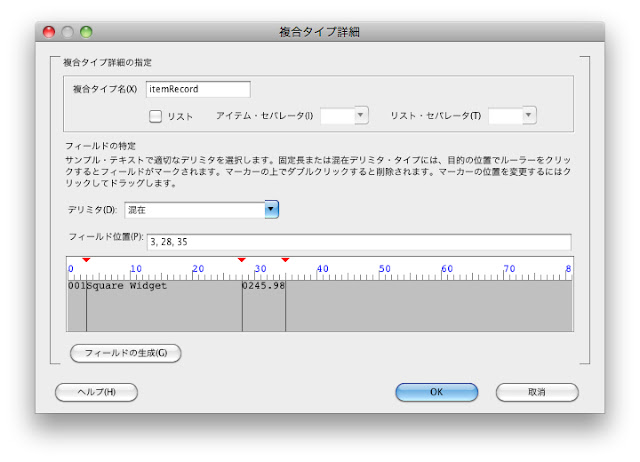
フィールドの定義ができたら、[フィールドを生成]ボタンを押すとC1、C2、C3というフィールドを作成します。各フィールド名を変更し、問題なければ[OK]を押して複合タイプを保存します。
- C1:itemNum
- C2:itemDesc
- C3:itemCost
次は、サマリーデータの複合タイプを定義します。
スキーマツリーのルート要素を選択して複合タイプ新規作成のアイコン
をクリックします。そして、サンプルデータからサマリーデータを選択して<new_complex_type>にドラッグアンドドロップします。
複合タイプの名前は"summaryRecord"に変更しておきます。
固定長フィールドとして、注文番号と注文日をマークし、[フィールドを生成]ボタンを押して、生成されたフィールド名を変更します。
最後の複合タイプで品目とサマリーデータを束ねるデータ型を定義します。
スキーマツリーのルート要素を選択し、複合タイプ新規作成アイコン
をクリックして生成される<new_complex_type>を選択して、鉛筆アイコン

をクリックします。
複合タイプ詳細の画面で、各フィールドの名前とデータ型を変更します。
- 1行目:item、データ型はitemRecord
- 2行目:summary、データ型はsummaryRecord
itemRecordは入力ファイル中で繰り返すので、その設定をするためにitemの行の右側にある鉛筆アイコン
をクリックします。
詳細画面で[最大発生数]を1からUNBOUNDEDに変更します。
さらに、ItemRecordを探す方法を指定しておく必要があります。各々の品目データには32桁目に"."があるので、これを使って品目データとサマリーデータとを区別することができます。[先読み]に32を指定して、[検索]に"."を指定し、[OK]を押して保存しましょう。
最後に注文を表す最上位の要素を作成します。スキーマツリーのルート要素を選択し、要素の新規作成アイコン

をクリックします。<new_element>をクリックして、鉛筆アイコンをクリックします。

要素名を”order”とし、データ型を”logicalOrderRecord”に変更します。[OK]ボタンを押して要素定義を保存します。
最後の設定で、以下のスクリーンショットのようになるはずです。[次へ]ボタンを押して、定義したソースを確認します。
[テスト]ボタンを押して定義のテストをしてみましょう。
緑の矢印アイコンを押してテストを実行しましょう。
すると喜ばしくないエラーが出てきます。このエラーはプロセッサが定義をチェックしている間にデータが不足した、というものです。つまり、itemRecordとsummaryRecordを区別できず、ファイル全体をitemRecordとして取り扱ってしまいました。ファイルの最後で”summary”部分が処理されずに残りましたが、これは必須項目です。
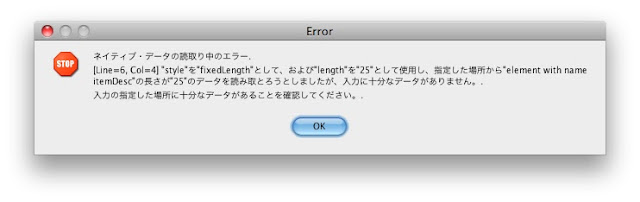
このエラーの根本原因は、itemRecordを判断するときに使う"lookAhead"定義が抜けているためです。これはネイティブフォーマットビルダ 11.1.1.4.0の不具合ですが、解決策があります。[キャンセル]を押してStep 4/4に戻り、手で
nxsd:lookAhead="32" nxsd:lookFor="."
を要素itemの属性maxOccursの後に追記します。
追記が終了したら、[テスト]ボタンを押してテスト画面の緑の三角形アイコンをクリックしてテストしましょう。今度はテストが成功し、ファイル中の最初の注文情報がファイルアダプタによって取り出されています。
以下は上図右側のペインに表示されているXMLデータです。
試してみよう!
上記手順を踏まなくても、
サンプルファイルとできあがった
スキーマファイルを使ってテストできます。
入力ファイルを頭から切り貼りするよりもずっと、この方法がよいでしょう。データが固定長なので、データ末尾のスペースに注意したり各行の最後にEnd-of-Lineが入っていることを確認することが非常に重要です。ダウンロードファイルは正しく整形されています。
テスト手順
- inputData.txtファイルをプロジェクトフォルダ中のxsdフォルダのような場所に保存
- inputData_6.xsdファイルをxsdフォルダに保存
- ネイティブフォーマットビルダのStep1で、[既存ファイルを編集]を選択し、inputData_6.xsdファイルを確認
- ネイティブフォーマットビルダのStep2で、inputData.txtファイルのパスとファイル名を指定
- テストページに移動し、テストを実行
- 属性lookAheadとlookForを消失するというウィザードのバグを思いだし、LogicalOrderRecord型に含まれる要素itemの属性maxOccursの後に、手で nxsd:lookAhead="32" nxsd:lookFor="." の追加が必要
原文はこちら。










































